Tech Notes
Table of Contents
Overview
The main ideas of CoreObject are:
Object graph persistence similar to CoreData, Apache Jackrabbit
Object graphs are partitioned into persistent roots; each persistent root acts as an isolated DVCS repository to keep track of the history of its object graph
DVCS doesn’t use file/directory abstractions
The DVCS is optimized for writing small commits (changing a few objects in an object graph), because commits are intended to map rougly to UI actions
All store/DVCS constructs are UUID-labelled
All objects are UUID-labelled at fine granularity, to facilitate incremental saves, and make diff/merge easy and accurate
A DVCS is an ideal base on which to implement undo/redo and collaborative editing
Architecture
Here is the rough layout of the CoreObject framework:
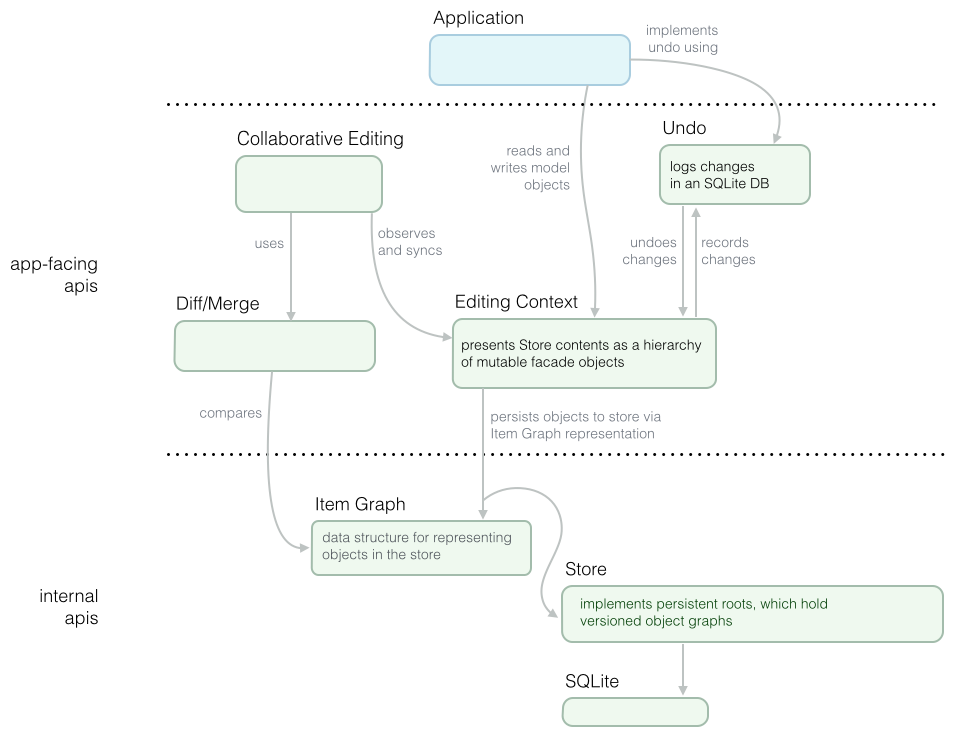
Store
The store is the bottom level in the CoreObject codebase. It implements the DVCS part and low-level object serialization.
A store is an unordered container of persistent roots which are stored in the same directory on disk and can share data internally. Conceptually, the store is an implementation detail in CoreObject whose only purpose is to represent persistent roots in an SQLite database in the host filesystem.
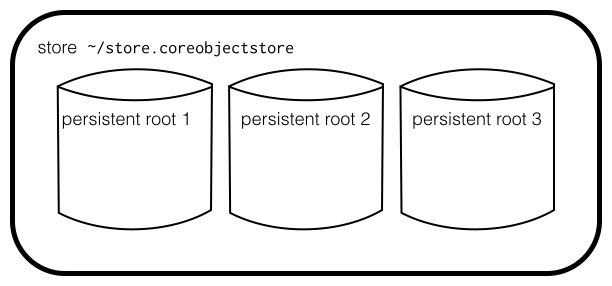
A persistent root is the "DVCS repository” part of CoreObject: it has a revision graph, and each revision is a snapshot of the object graph represented by the persistent root. We borrowed the term persistent root from object-oriented databases. You can also think of a persistent root as a versioned document.
Object Graph
We use the term “item graph” to mean a serialized object graph (either in store or in memory), and object graph to mean the mutable in-memory representation.
Unlike most DVCS’s, we don’t use a directory/file abstraction in CoreObject, and there’s no facility for checking out a working copy of a persistent root into a filesystem. The item graph is intended to subsume the role of a filesystem, handling the file organization features that you would use a filesystem for, and also handle the role of a structured file format like JSON.
An item graph starts with a root item and consists of that item plus all items reachable by following references.
Here’s an example item graph that could be stored in a persistent root:
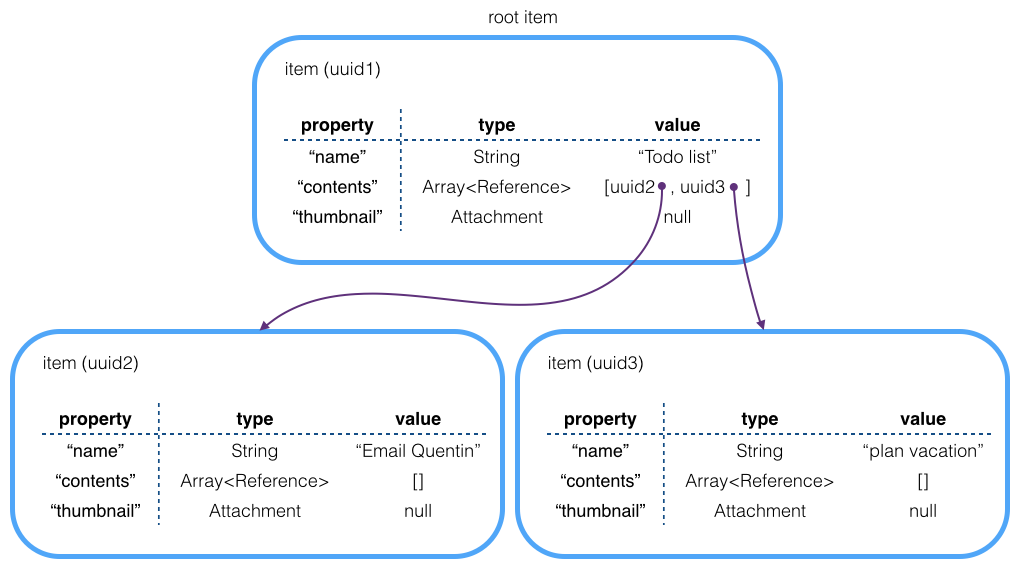
The items in the item graph follow our own object model. Why invent a new object model instead of using e.g. JSON?
We felt is was necessary to have:
UUIDs on every item. This facilitates diffing item graphs, and incremental saves (writing out exactly the set of modified items)
First class UUID-based references (the purple arrows above). First-class meaning they are strongly-typed object reference, not stored in a string or integer like you’d do in JSON.
For item graph diff/merge to be useful, it needs to be aware of references. Likewise, we explicitly support unordered and ordered collections at this level so the diffs are semantically meaningful, and provide good input for the merge algorithm.
We also support first-class references which point to another persistent root in the store; these links are what allow CoreObject to take over the organizational role of a filesystem (Tags or folders, serialized as items in one persistent root, can contain links to other persistent roots which are documents, for example.)
Less importantly, it was convenient to be able to make attachments a first-class type, so we can garbage-collect them.
CoreObject would be more compatible with the outside world if it used a standard format like JSON, but the resulting system couldn’t meet our end goals without following the above conventions, so we decided it was cleaner to force them on all data stored in CoreObject by having our own object model.
Once we decided to have our own object model, it was natural to make a custom binary serialization format. The result is fast and the code is simple. Here is the binary serialization of the root item from the diagram above:
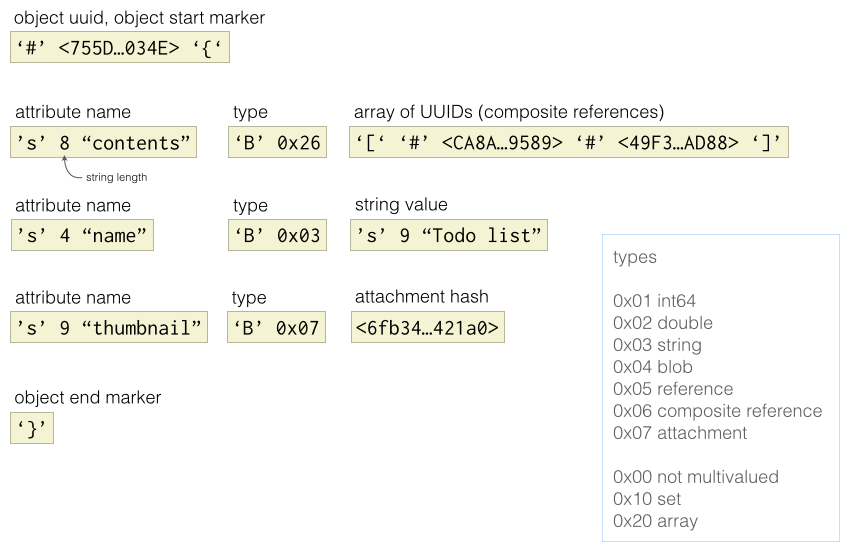
Note that the item’s attributes are sorted; this ensures there is only one valid binary serialization for a given item. (If you use the unordered set multivalued type, the elements in the set are sorted at serialization time for the same reason). Strings are UTF-8, integers are little-endian.
The binary serialization of the entire item graph is essentially the serialization of each item concatenated together.
Delta Storage
One of our design guidelines was that commits had to be very fast, since we wanted to be able to make them after almost every UI action. A solution involving serializing the entire document the user is editing on every commit wouldn’t scale with large documents.
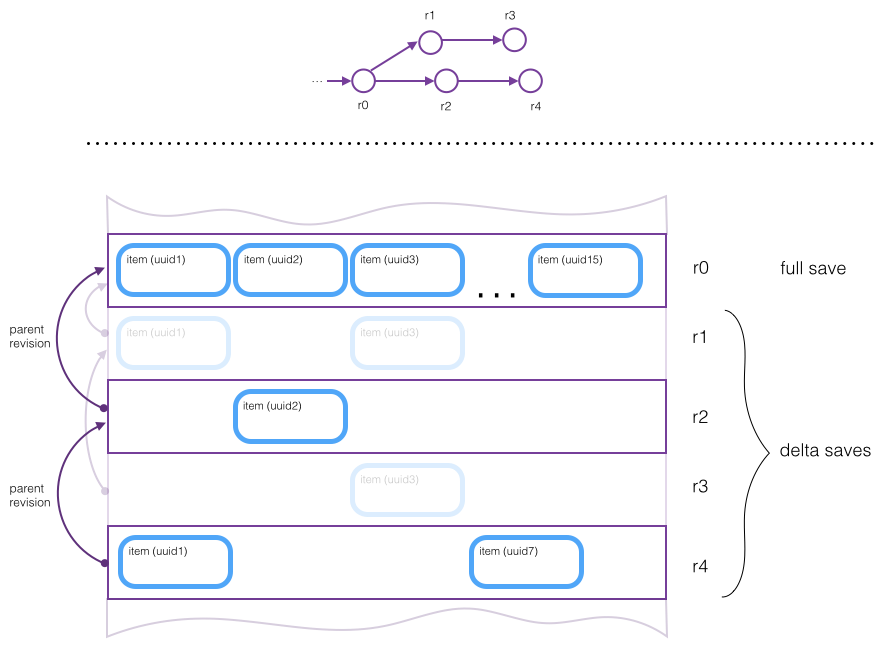
The solution we came up with is, when you write a new revision of a persistent root, you just pass in the set of items which were modified since the parent revision. This requires the API user to track which objects were modified and pass in the correct ones. (Occasionally, the store will decide to write out a full save; this is transparent to the user of the store API. This is inspired by Mercurial’s revlogs.)
Here’s an example of how a revision graph with 5 revisions might be represented in the store. Recall that the content in a revision is an item graph; the blue “item” boxes in the diagram represent binary-serialized items. The three darkened purple rectangles are the revisions that would be needed in order to reconstruct the item graph of revision r4.
Attachments
CoreObject supports attaching large files to a store (images, movies, etc.) Attachments must be referenced through a special attachment reference type in an item, because CoreObject tracks references to attachments and garbage-collects them when there are no remaining references.

This arrangement has several nice characteristics:
since they're store by hash value, attachments are automatically de-duplicated
copying an item with a reference to an attachment doesn't require copying the attachment data
they don't introduce any new behaviour with respect to deletion
Persistent Roots & Branches
Here's a more complete picture of the state associated with a persistent root:
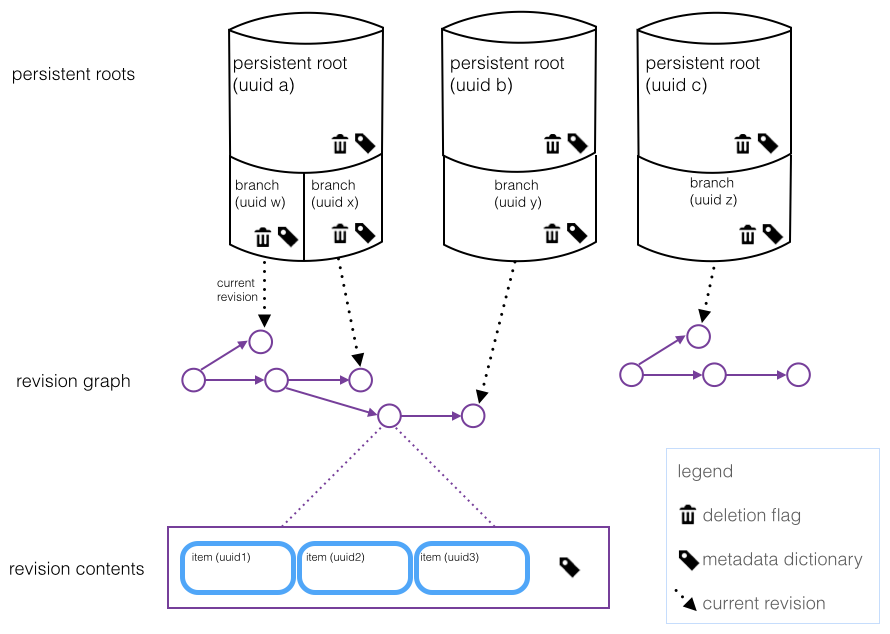
A persistent root can have several branches. Branches are much like in git; they are named pointers to revisions. Each persistent root also has a current branch, just like a git repository's HEAD.
Branches are designed so that you can ignore them if you don’t need them, but if they make sense in your application (for working on several variations of a document, for example), they’re available.
CoreObject also supports copying persistent roots, such that the copy uses the same revision graph as the persistent root it was copied from - so we call it a cheap copy. There’s no danger of the copies interfering with each other, because the revision graph is immutable (except when a store is garbage-collected.)
At a deep level, a cheap copy is not much different from a branch, so if desired you can expose this in an application - ProjectDemo allows the user to turn a branch into a copy, and vice-versa.
Deletion
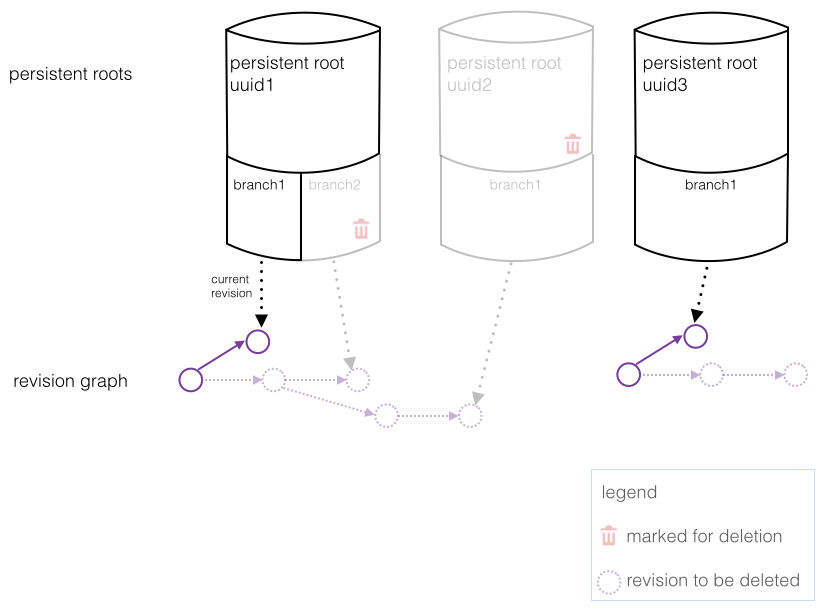
Persistent roots and branches must be explicitly deleted by the user, analogous to deleting a file.
However, we wanted to design for the use case of a user deleting a persistent root by accident - almost every change in CoreObject is undoable. To implement this, each persistent root and each branch has a deletion flag, so initially when you delete a persistent root, nothing is actually deleted, but it's trivial to undo the deletion.
To actually free up disk space, there is a “finalize deletions” command you can perform on a store. This permanently ereases all persistent roots and branches that were marked as deleted, and is non-reversible.
Revisions, unlike persistent roots and branches, are garbage collected, and users have no explicit control over their lifetime. There are a few motivations for this behaviour:
Ordinary use of CoreObject-based apps is expected to create divergent revisions. (e.g. in a text editor: "type, undo, type, type, type” would create a divergent revision.) If the user doesn’t go back and save these divergent revisions by creating branches for them, it makes sense to automatically delete them
Fits well with the overall conceptual design of CoreObject. Revisions are not a concept users need to worry about - branches and persistent roots are - so it makes to garbage collect revisions, but use explicit deletion for branches and persistent roots
Something we want to support, but is not yet implemented, is the ability to erase the distant past history of a persistent root’s revision graph (e.g. "delete history older than 6 months").
Finally, items in a revision’s item graph are garbage collected. This let us define an item graph as “a root item, plus the set of items reachable by following references”. One nice side-effect of this definition is, it’s acceptable to have have extra “garbage” items in a set of items that makes up an item graph - they will simply be ignored - and the store exploits this (see the Delta Storage section) to simplify its implementation. Another nice side effect is, when diffing two item graphs, we don’t need to consider deletion as a special case. If all references to an item are removed, the item ceases to be a part of the item graph; we don’t need to pollute diffs/merges with special “delete item” commands.
Diff/Merge
The main difficulty in diffing two pieces of structured data is figuring out a correspondence between objects in the two documents (a lot of research on diffing arbitrary XML boiled down to heuristics for identifying the “same” object in the two document versions being compared). CoreObject sidesteps this problem by forcing all objects to have a UUID label.
Given the knowledge of the correspondence between objects in two documents, the remaining diff algorithm is pretty trivial. Our diff algorithm looks something like this:
Given an original item graph A and modified item graph B,
for each object O in B but not A, record it as an object insertion
for each object O in B that is modified vs. that object in A:
for each attribute attr of O that is modified in B vs. A
if attr is an unordered multivalued attribute or relationship (i.e. a set), record an "unordered multivalued edit”, along with the set differences B[O].attr - A[O].attr (i.e. elements added to the set) and A[O].attr - B[O].attr (i.e. elements removed from the set)
if attr is an ordered multivalued attribute or relationship (i.e. an array), invoke the Myers LCS algorithm on the two arrays, and record the resulting array edits
otherwise, attr must be a univalued attribute or relationship, record an edit “O.attr = <new value>"
Merge essentially involves combining all edits from the two diffs together, then marking conflicts. Presenting a visualization of this type of diff (and any conflicts) in a UI is still an open question.
Here’s a pair of item graphs and the resulting diff:
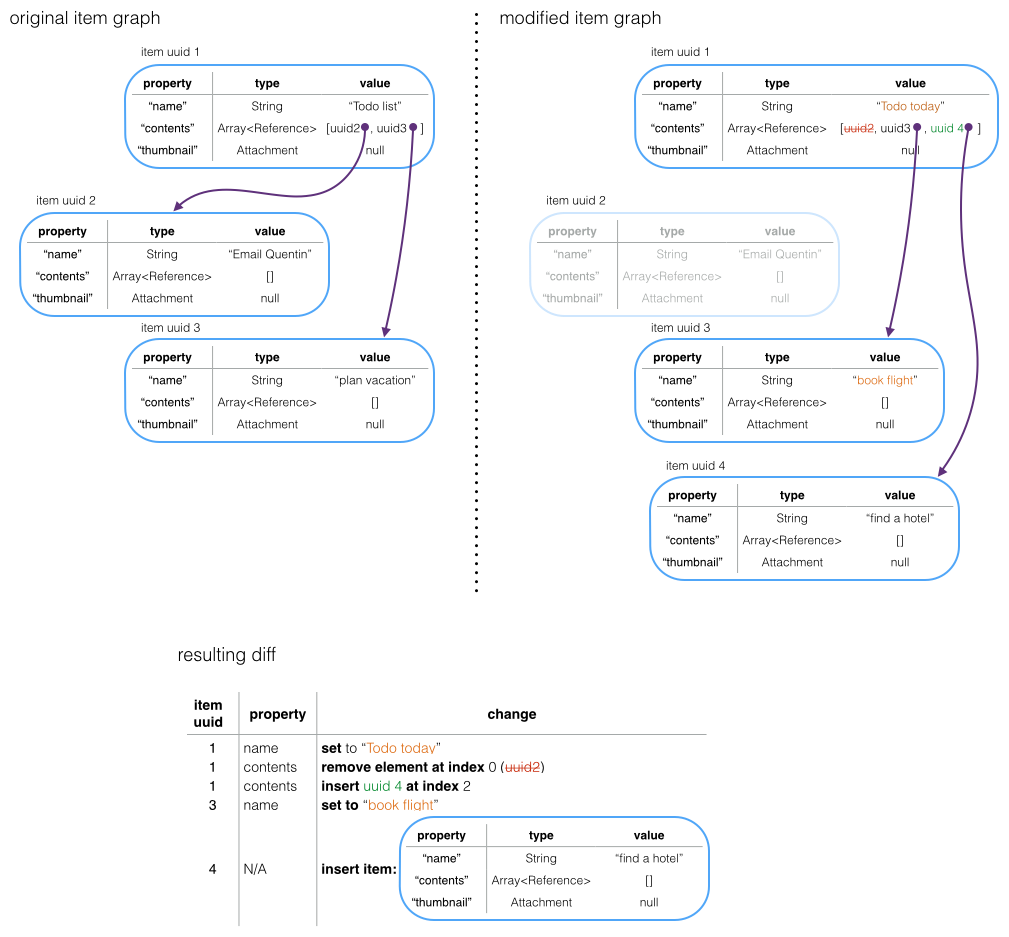
For more details and background, see the paper Difference and Union of Models.
We also support plugging in alternative diff/merge algorithms for particular item types when the default one isn’t suitable. CoreObject includes an example of this, a unfinished prototype of attributed string (i.e. styled text) diff/merge.
Editing Context
You can use the Store API on its own, but it's quite cumbersome. The Editing Context layer of CoreObject just presents a store as a set of mutable objects, which track changes you make to them, so when you call the -commit method, the editing context builds up an appropriate transaction and commits it to the store.
COEditingContext is a mutable facade for a store
COPersistentRoot is a mutable facade for a persistent root
COBranch is a mutable facade for a branch
COObjectGraphContext is a mutable facade for an item graph
COObject is a mutable facade for a single item in an item graph
Like other object databases and object graph persistence systems, you must define a schema/metamodel for your model objects to follow (see class ETEntityDescription and ETPropertyDescription). Each item in an item graph has a “entity name” property which determines which entity description it uses.
Undo
CoreObject comes with a ready-made undo system to use in your applications. Superficially, it's quite ordinary; based on the Gang of Four command pattern, but it also has some unusual features.
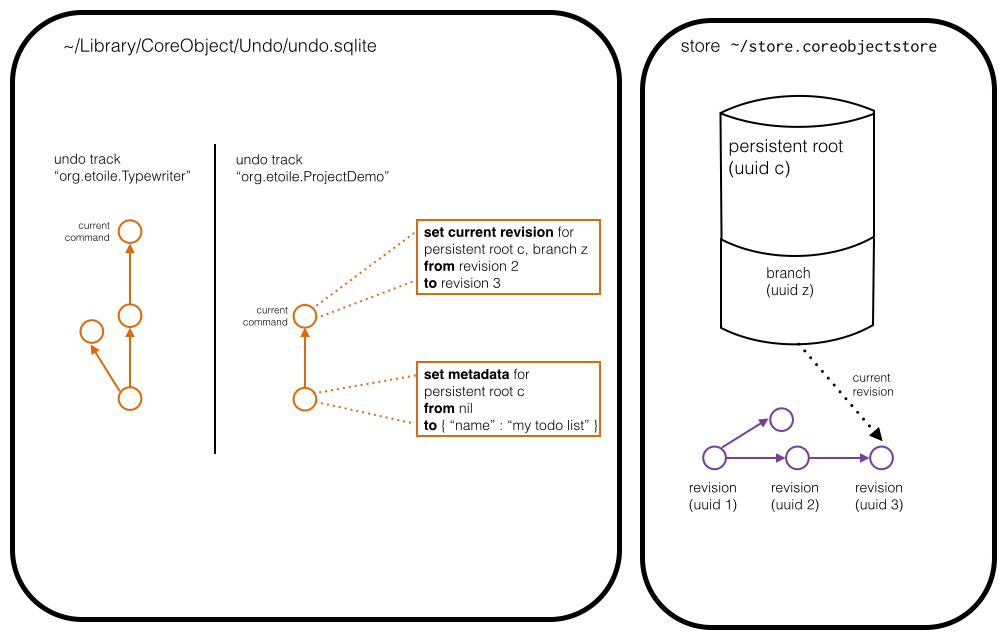
First, the commands and undo stacks are persisted in a SQLite database (separate from the CoreObject store.) This makes application restarts transparent.
Second, while most undo systems would have a set of command objects that track changes to the application’s model objects, the CoreObject commands track things one level of abstraction higher up; they record mutations made to a CoreObject store. The nice thing about this is, the complete list of commands is:
Persistent Root
Create, Delete, Undelete
Change Metadata
Set Current Branch
Branch
Create, Delete, Undelete
Change Metadata
Set Current Revision
which cover all possible changes you can make to a CoreObject store (except invoking garbage collection, which is destructive and non-undoable.)
This means as your application evolves, as long as you store all of your state in CoreObject, you’ll never have to write another undo command.
Another unusual feature: all of these commands can be applied to a store that’s in a different state than when the command was recorded. The most common command, "Set Current Revision”, represents the user committing a change to a branch, or reverting some changes, and the command contains the initial and final revision UUID’s. If the user asks for the command to be undone (or redone), and the branch doesn’t have the same current revision as when the command was recorded, CoreObject generates a new revision which cherry-picks or reverts the required changes. This is what gives us selective undo, per-user undo in collaborative editing for free, and the ability to have an undo stack per viewport with multiple viewports on the same document for free.
Finally, we allow branches in the undo command graphs, rather than restricting it to a stack. This is not a major feature (in fact it was a late addition), but gives you an extra layer of security against losing a change.
Here’s an example undo store showing two undo tracks and their undo commands:
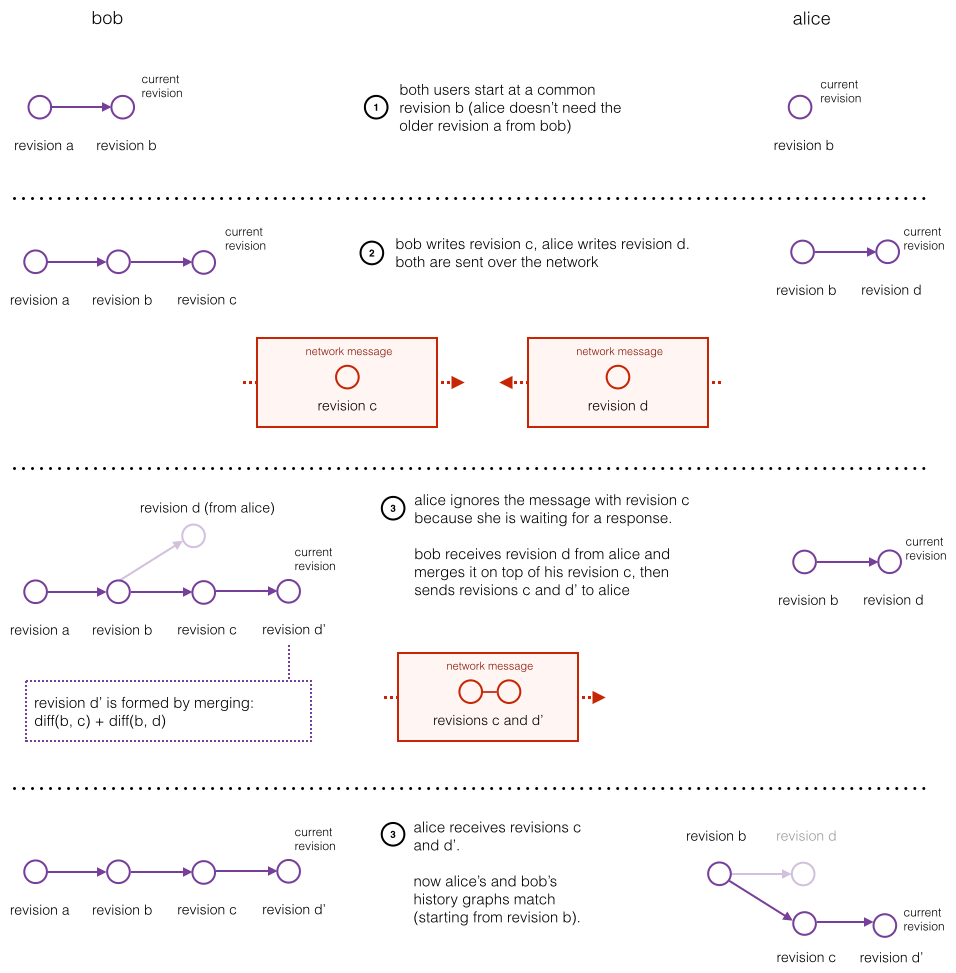
Collaborative Editing
Collaborative editing support was the last part of CoreObject we wrote.
On one hand we had vague ideas of transparently supporting collaborative editing of any document from the start, but other than having the general idea in mind, no collaboration-specific features were added to the main parts of CoreObject.
The syncing algorithm is inspired by https://neil.fraser.name/writing/sync/, but instead of syncing diffs of the application model objects (e.g. character-level diffs for a text document), the collaborative editing code syncs persistent root revisions (following the same philosophy as the undo system.)
This lets all users see the same sequence of revisions, see who made which changes, and lets the CoreObject undo system work seamlessly, so each user can undo his or her own changes.
Of course, at the end of the day, we still have to merge character-level changes (for a text document) the same way OT does. We just consider it (and implement it) as a regular usage of CoreObject’s diff/merge code, and not part of the collaborative editing algorihm.
Here’s an example of how the collaborative editing system handles two users making an edit simultaneously: